Building on my recent post about Kwiks and the AI moderation system that I designed when I was working for them I wanted to write about a couple other neat systems that I designed to solve another similar problem: video tagging. This will outline the problem and the approach that I took to solve this and build on to our moderation system in the process while not getting too deep into the development process. In future posts we’ll talk about using this system in some more complex works and how those were made.
First, if you didn’t read the last post, a bit of background - I was freelancing on Upwork when I met someone working at Kwiks who was recruiting for a team to develop this new social media app similar to TikTok. I liked the vibe and I was looking for something a little more stable so I decided to give it a try. I was the first backend developer on staff and my infrastructure experience put me in charge of the backend and infrastructure right from the beginning of development. During my year at Kwiks I built out their backend and a complex scalable infrastructure designed to reach millions of users across the globe.
The Problem
Our mission at Kwiks was to develop a video-centric social media platform similar to TikTok and one of the most important features of these platforms is their recommendation engine that is able to accurately suggest videos to users that they will see when scrolling through a feed of videos. This presents some unique challenges because unlike some other platforms where suggestions can be generated over time these suggestions had to be generated as the paginated feed data was being handed off to the user. This more “live” centric system had to be fast and accurate and it’s a huge selling point for video sharing platforms like this so it was vital to our success.
One of the challenges in this process is getting data about the context of each video. In order to understand what the user likes to watch we need to know what’s in the videos they are interacting with or watching the most and we need this data in a way that a machine can understand so that we can move context through independent systems as recommendations are generated. As the defacto backend and infrastructure guy at Kwiks the responsibility fell on me to figure out how to make this work so with my previous understanding of AWS Rekognition I got started on the solution.
The Solution
While I knew we could use Rekognition for content tagging I thought about my experience with social platforms and that sometimes the content of the video was not nessicarily the focus of the content. Have you ever seen a short blank clip with someone talking? That’s what I had in mind, so I knew we had to have an extra service in here as well to make things more well rounded as an update to our existing moderation system. Ultimately I decided to add AWS Transcribe to the stack so that we could have a text transcription of the video as well. This would also be useful later to have subtitles and things like that so it was a win-win. I also noticed that Transcribe has a “Toxcitity” detection and so I wanted to add that to our exsiting moderation tooling.
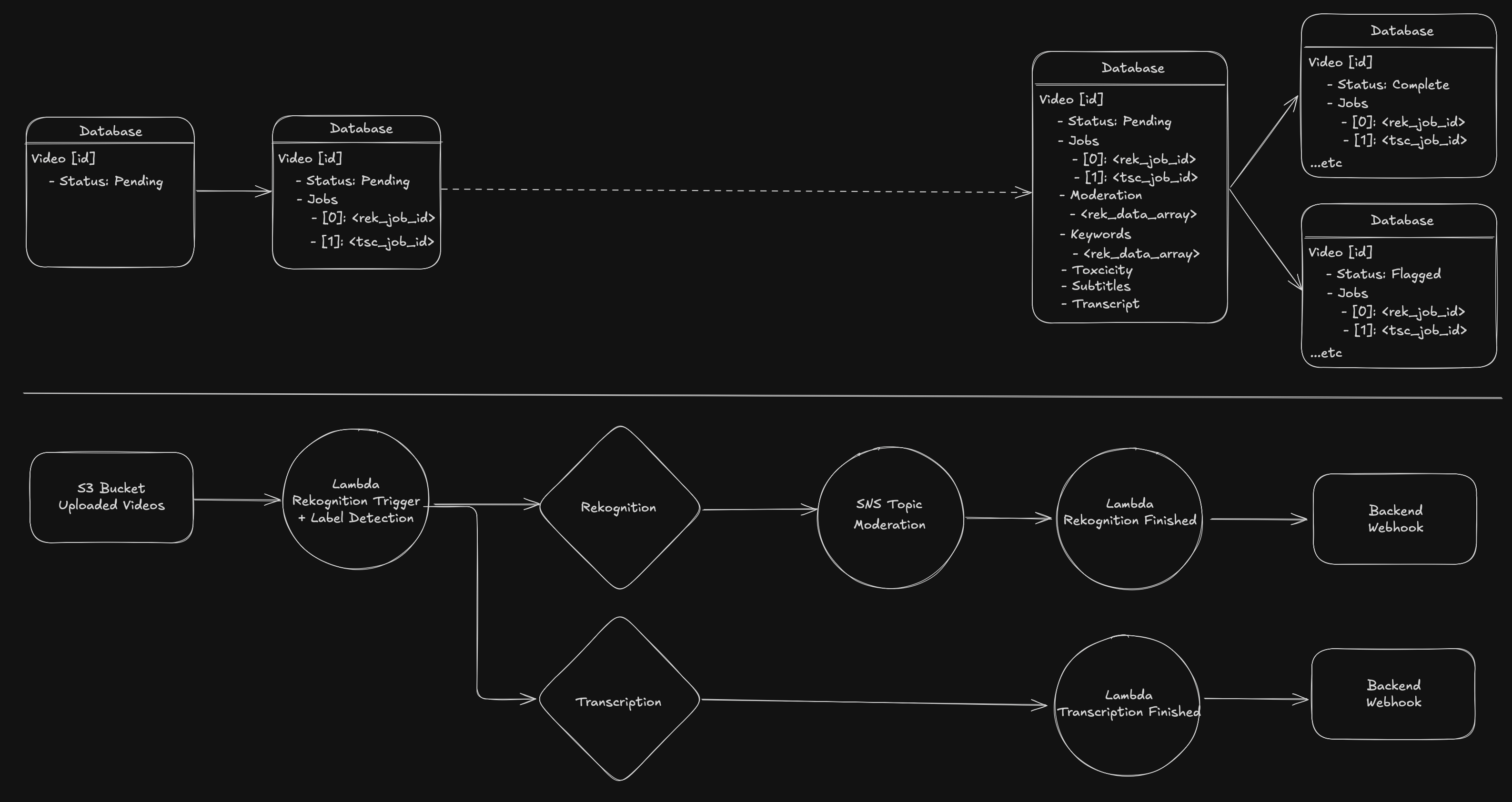
The first step was setting up an IAM role for Rekognition’s label detection to access the data within the S3 buckets so that it could use the videos inside. The second step was setting up an SNS topic so that we can be notified when the Rekognition label detection task has completed because Rekognition runs async and doesn’t have a determinate time of completion though it’s usually not very long which is helpful because we need to hold uploaded videos until these processes have completed.
As you can see in the top section of the graphic above, the video object that tracks the file as it moves through the system has a status field that starts out as pending when the video is uploaded. This has more statuses for the uploading process too but we use this database object to tell the uploader what’s happening with their video. When the frontend reads the pending status we let the user know that the video is moving through our systems and it should be available soon. Modifying the existing set up with Rekognition’s JobId we also add the transcription JobId so that we can have that for later as well. Once the video has finished initial upload and this status is set our Lambda functions are triggered automatically with information about the file such as name and key allowing us to pass that off to Rekognition and Transcribe to kick off the label detection and transcription. We also pass along the SNS topic to Rekognition so that it can signal completion when it’s done.
When Rekognition completes the SNS topic triggers the “Rekognition Finished” lambda which sends a request for the Rekognition data that was generated from the video. We take that information then save it to the video object in the database. With labels, we’re storing all of the information including which time in the video the label was detected but we also have a more simple list of strings as well in case we needed that data too.
When Transcribe completes the Lambda “Transcribe Finished” is triggered automatically and we take several values from this to store in the database including the transcript file uri, subtitle file uri and “Toxicity”:
1 | const avgToxcitiy = average(toxcitiy, 'toxicity'); |
We store all of this data in the video object in the backend so that when our webhooks are called we can check if all jobs have been completed and then use the “Toxicity” data in conjunction with the existing moderation system to determine if the video is allowed or not.
The Outcome
With this data our moderation system became far more robust but more importantly we had labels about the content of videos and their transcription which would allow us to build a far more robust recomendation system later on.. while I won’t get into too much detail about that yet this system was very robust and working well. We decided to let it process videos for a while while we figured out the best way to build a robust recommendation system around the new data that we have.